
Splunk Enterprise is a powerful platform designed to help organizations gain valuable insights from machine-generated data. Behind its user-friendly interface lies a streamlined, yet robust architecture that enables it to handle large volumes of data efficiently.
Understanding the fundamental components and design principles of Splunk's architecture is crucial for setting up a successful deployment. In this article, we'll explore the most common architectures and topologies in use for Splunk today.
Introduction to Splunk Architecture
Splunk Enterprise's architecture is composed of several key components that work together to provide a seamless data analytics experience. One of the simplest forms of this architecture is the Single Instance, where all functions are carried out by a single Splunk server. This includes data input and indexing, searching, and visualization.
For larger data volumes, Clustered Indexers and Search Heads come into play. These are Splunk components configured in a clustered environment to ensure high availability and disaster recovery. Clustered Indexers distribute data across multiple nodes for indexing, while Search Heads handle search management tasks.
The architecture is divided into several tiers: Search Tier, Indexing Tier, Collection Tier, and Management Tier. These tiers represent the flow of data from its raw form to the point of generating insights. The Collection Tier is responsible for data ingestion, the Indexing Tier for data storage and retrieval, the Search Tier for querying and rendering data, and the Management Tier for overall control and configuration.
Multisite and Single Site architectures cater to organizations spread across multiple geographical locations or confined to a single location respectively.
Data storage in Splunk is split between Hot/Warm - Cold Storage. Hot/Warm storage holds recent data readily accessible for quick analysis, while Cold Storage contains older, less frequently accessed data.
Splunk can also integrate with S3 Compatible Storage for cost-effective, scalable storage solutions, and uses Syslog,HEC, and HF for data collection and forwarding.
Key Components of Splunk Architecture
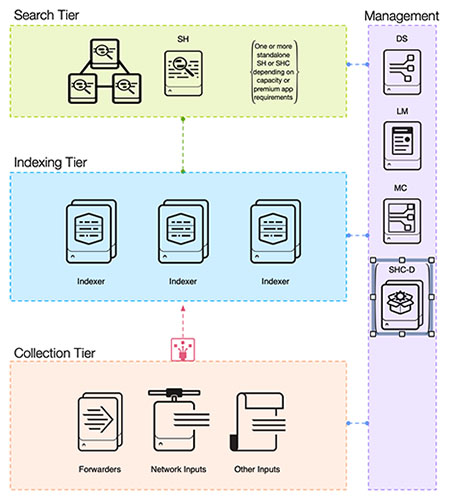 Splunk's architecture is built on a series of interconnected components, each playing a vital role in collecting, indexing, searching, and visualizing data. At the heart of this architecture are three tiers plus a management layer.
Splunk's architecture is built on a series of interconnected components, each playing a vital role in collecting, indexing, searching, and visualizing data. At the heart of this architecture are three tiers plus a management layer.
The Search Tier consists of one or more search heads which run the user interface and coordinate search jobs, dispatching them to indexers and merging the results. Search heads can be configured as one or more stand-alone instances or work together in a search head cluster to distribute the workload.
The Indexing Tier contains Indexers, which are the powerhouse in the Splunk architecture - they ingest high volumes of raw data, transforming it into searchable events. They also handle the task of data compression, reducing storage costs while maintaining quick search speeds.
Depending on your goals and the complexity of your environment the Collection Tier may contain a variety of components, including Universal Forwarders, Heavy Forwarders, Syslog Servers, HEC Collections (which are technically a component of the Indexer). Universal Forwarders, sometimes called the Splunk agent, are installed on servers and desktops to collect log files and metrics. Heavy Forwarders are frequently used to collect data from sources that leverage API's. Syslog Servers receive data from network devices such as routers and firewalls and route that data to Splunk using a Forwarder.
The Management Tier contains all components that control and monitor the operation of Splunk, Deployment Server, License Manager, Search Head Deployer, Cluster Manager and Monitoring Console.
Deployment servers streamline the process of distributing configuration updates to forwarders and other Splunk components, ensuring consistency across your deployment. The Cluster Manager controls the indexer clusters to ensure high availability and data integrity. It coordinates replication and search factor configurations among all peers in the cluster. The License Manager, on the other hand, is responsible for enforcing license limits across all Splunk instances. The Search Head Deployer pushes apps and configurations to the search heads, but only in a search head cluster. The Monitoring Console enables Splunk administrators to monitor the health and performance of a Splunk deployment, be it a standalone instance or a distributed environment.
Finally, Splunk has two data storage methodologies: Classic Storage and Smart Store. Both have distinct advantages depending on the usage scenario.
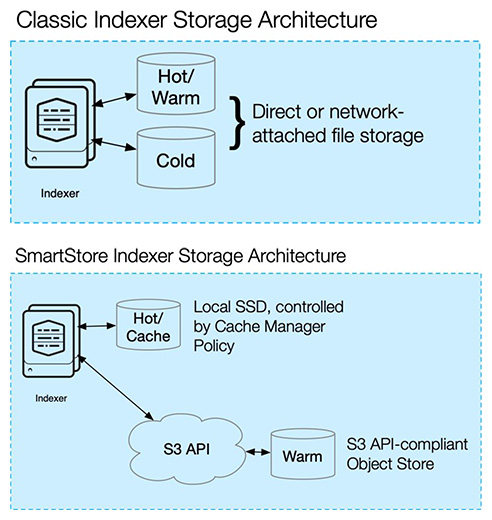 Classic Storage stores both hot/warm and cold data directly on Indexers. As data is ingested, it stays on the indexer until it is either aged out and deleted or moved to cold storage. While this traditional model offers simplicity, it demands high I/O and can lean towards expensive due to the need for a large amount of high-performance storage on each Indexer.
Classic Storage stores both hot/warm and cold data directly on Indexers. As data is ingested, it stays on the indexer until it is either aged out and deleted or moved to cold storage. While this traditional model offers simplicity, it demands high I/O and can lean towards expensive due to the need for a large amount of high-performance storage on each Indexer.
On the other hand, Smart Store decouples compute and storage layers, leveraging the power of S3-compatible object storage for storing indexed data and leveraging local storage on Indexers for cache. This allows Splunk deployments to scale up to handle large data volumes without having to scale the Indexer storage proportionally. It offers cost savings as infrequently accessed data can be stored in cheaper cold storage. However, planning and management of cache are essential for optimal performance in a Smart Store setup.
Note on Manager vs. Master: Several years ago Splunk changed terminology and configurations from Master to Manager. Looking through the Splunk configurations you may see both Master and Manager directories. Manager will take precedence over Master. If Manager contains any configurations, Master will be ignored completely.
Designing and Scaling Splunk Architecture
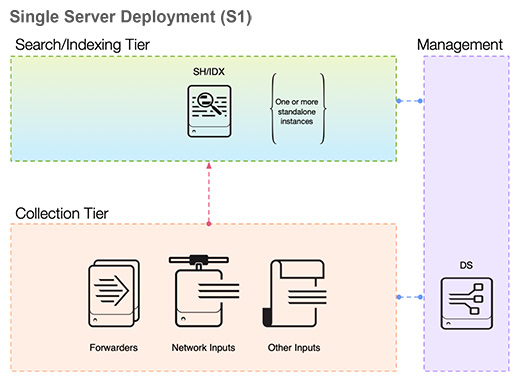
Splunk architecture can be tailored to suit specific needs, resulting in diverse topologies. A single-instance deployment is the most basic, where all Splunk functionalities are housed within a single server. This is ideal for small-scale environments or for development and testing purposes.
An Indexer Cluster is a group of Splunk indexers configured to replicate each others' data, ensuring high data availability. This deployment is preferred when dealing with large data volumes that require distributed searching and indexing. Today, all on-premise Splunk environments with more than one indexer operate in a cluster topology.
A Multisite Cluster is another vital component of Splunk architecture. This deployment type expands on the Indexer Cluster model by distributing the indexers across multiple, geographically dispersed sites. Each site operates as an independent, fully functional Indexer Cluster, but they collectively form a unified data storage and search system. The primary goal of a multi-site cluster is to provide disaster recovery and data availability even in the event of an entire site failure. Data is replicated across sites, ensuring that a copy of the data is always available even if one site goes offline. This makes the multi-site cluster an ideal choice for organizations that require the highest level of data resilience and availability.
A Search Head Cluster, consisting of a group of search heads working together, provides high availability and scalability for searching. The cluster members coordinate to ensure that all searches and knowledge objects are kept in sync. This topology is best for environments with heavy search loads to distribute the load across multiple search heads.
Cloud deployments offer the advantage of scalability and maintenance-free operation. Splunk Cloud is fully managed by Splunk, ensuring high availability and secure data protection. It's an excellent choice for organizations seeking to leverage Splunk's capabilities without the need for hardware or dedicated personnel to manage it.
The most common architectures we build at Conducive are Splunk Cloud and on-premise Single or Multi-Site Indexer Clusters. On-premise architectures may be built with one or more Search Heads, almost always stand-alone. Occasionally we architect Search Head Clusters, but only for specific use cases.
 Splunk Cloud Architecture is a fully managed service that delivers the capabilities of Splunk Enterprise without the need for infrastructure management. It provides the scalability to accommodate large volumes of data and the resilience to ensure data availability. The architecture is designed to handle data ingestion, indexing, searching, and visualization while maintaining high performance and security standards. The data is stored in indexes that are spread across multiple, geographically dispersed sites to support disaster recovery and high availability. The Splunk Cloud architecture eliminates the need for organizations to maintain their hardware or dedicate personnel to manage the system, making it a convenient, scalable, and reliable solution for large-scale data analytics.
Splunk Cloud Architecture is a fully managed service that delivers the capabilities of Splunk Enterprise without the need for infrastructure management. It provides the scalability to accommodate large volumes of data and the resilience to ensure data availability. The architecture is designed to handle data ingestion, indexing, searching, and visualization while maintaining high performance and security standards. The data is stored in indexes that are spread across multiple, geographically dispersed sites to support disaster recovery and high availability. The Splunk Cloud architecture eliminates the need for organizations to maintain their hardware or dedicate personnel to manage the system, making it a convenient, scalable, and reliable solution for large-scale data analytics.
Although 95% of Splunk Cloud is hosted and managed by Splunk in the cloud, a few on-premise components are still required to move data from your data center to Splunk Cloud. These On-Premise Components include the Heavy Forwarder / Syslog Server, and the Deployment Server. Both of these components can run in virtual machines. Additionally, Universal Forwarders are usually deployed to customer owned servers to collect forward server logs to Splunk Cloud.
The Syslog Server is another crucial element that collects syslog data and leverages the Heavy Forwarder to forward it to the Splunk Cloud indexers. The Deployment Server is responsible for managing and coordinating the configuration of the Forwarders.
These on-premise components of Splunk cloud provide flexibility and control over data forwarding, management, and configuration, thereby enhancing the overall efficiency and reliability of your Splunk environment.
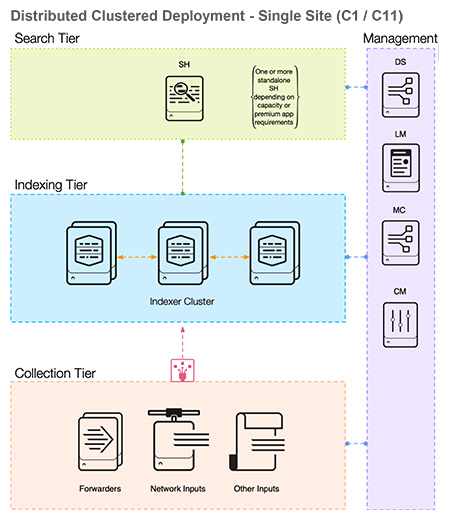 Single Site Indexer Cluster is another architectural design within the Splunk Enterprise platform that provides a high level of data availability and recovery. It comprises multiple indexers acting as a cluster to ensure data resilience. One node within the cluster is dedicated as the manager node (Cluster Manager), which coordinates the activities of the others, known as peer nodes (the indexers). This cluster formation offers the benefit of data replication across the nodes, providing a safety net against data loss. This design is particularly useful for organizations that need to handle large volumes of data within a single geographical location, while ensuring data availability and system performance.
Single Site Indexer Cluster is another architectural design within the Splunk Enterprise platform that provides a high level of data availability and recovery. It comprises multiple indexers acting as a cluster to ensure data resilience. One node within the cluster is dedicated as the manager node (Cluster Manager), which coordinates the activities of the others, known as peer nodes (the indexers). This cluster formation offers the benefit of data replication across the nodes, providing a safety net against data loss. This design is particularly useful for organizations that need to handle large volumes of data within a single geographical location, while ensuring data availability and system performance.
The cluster has two levers to manage data storage, the search factore and replication factor. The search factor determines the number of searchable copies of data are held in the cluster. The replication factor determines the total number of copies. Replication factor cannot be less than the search factor. The number of indexers must be at least replication factor plus one. If the replication factor is larger than the search factor, the additional buckets will only contain raw data. A typical configuration is a search factor of 2 and a replication factor of 3.
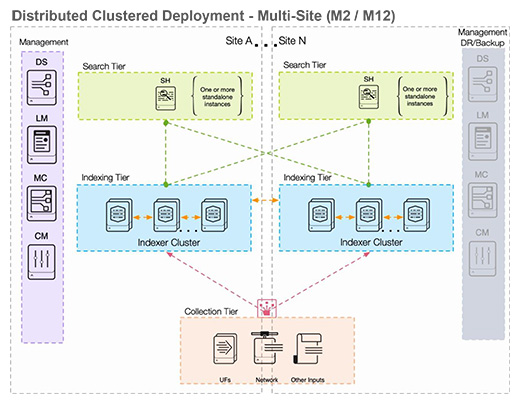 Multisite Indexer Cluster is an evolution of the single-site indexer cluster, designed for organizations operating across multiple geographical locations. This architecture extends the data resilience and availability features of a single-site cluster by replicating the data across multiple sites. Data ingested at any site is replicated to others to ensure data availability even in the event of a site failure. This design improves search performance by balancing load across multiple sites, providing a robust architecture for handling vast amounts of data in a multisite environment. Additionally, it bolsters disaster recovery capabilities by ensuring data is safely replicated across several geographical locations.
Multisite Indexer Cluster is an evolution of the single-site indexer cluster, designed for organizations operating across multiple geographical locations. This architecture extends the data resilience and availability features of a single-site cluster by replicating the data across multiple sites. Data ingested at any site is replicated to others to ensure data availability even in the event of a site failure. This design improves search performance by balancing load across multiple sites, providing a robust architecture for handling vast amounts of data in a multisite environment. Additionally, it bolsters disaster recovery capabilities by ensuring data is safely replicated across several geographical locations.
In addition to the search and replication factors, a third lever is enabled which sets the minimum number of copies at each site. Additionally, Splunk allows for site and search affinity which limits data unnecessarily traversing data centers.
 A Search Head Cluster in Splunk architecture is a group of search heads that work in unison, enhancing the scalability and reliability of Splunk's search functionality. The cluster's primary role is to coordinate the dispatching and execution of searches, distributing the workload evenly across multiple search heads. This parallel processing significantly improves the speed and efficiency of searches over large volumes of data. The Search Head Cluster also provides fault tolerance - if a search head fails, the remaining nodes can continue operations uninterrupted. This design ensures continuous search capabilities, critical for organizations that require real-time insights and analysis of their data.constant availability and uninterrupted access to search capabilities, a critical aspect in data-intensive organizations. Search head clustering is rarely used with Enterprise Security.
A Search Head Cluster in Splunk architecture is a group of search heads that work in unison, enhancing the scalability and reliability of Splunk's search functionality. The cluster's primary role is to coordinate the dispatching and execution of searches, distributing the workload evenly across multiple search heads. This parallel processing significantly improves the speed and efficiency of searches over large volumes of data. The Search Head Cluster also provides fault tolerance - if a search head fails, the remaining nodes can continue operations uninterrupted. This design ensures continuous search capabilities, critical for organizations that require real-time insights and analysis of their data.constant availability and uninterrupted access to search capabilities, a critical aspect in data-intensive organizations. Search head clustering is rarely used with Enterprise Security.
The cluster consists of three components: the captain, the members, and the dynamic captain election process. The captain, an elected member of the cluster, coordinates activities across the cluster, such as job scheduling and replication, while other members execute searches and provide results. The dynamic captain election process ensures that if the current captain encounters issues, another member can readily take its place, maintaining smooth operations.
Moreover, the search artifacts, such as search results and search jobs, are replicated across multiple cluster members, strengthening the fault tolerance of the architecture. This replication ensures that if a cluster member fails, the search would still be available through another member without any loss of data or interruption to the user.
Best Practices for Splunk Architecture Optimization
When optimizing your Splunk architecture, there are several best practices to consider. First, capacity planning is crucial. Understand your data ingestion rate and ensure your indexers can handle the load. Your Splunk license must be sized appropriately to handle your data volume. Second, you must take into consideration your data center, resiliency and redundancy needs. Leverage single or multi-site indexer clustering to protect against data loss and downtime.
Consider using dedicated search heads for specific tasks such as Enterprise Security, long-running searches or heavy visualization workloads. This approach can help balance the workload and improve performance.
Ensure that you design for the correct search and replication factor when building an indexer cluster. A good rule of thumb is search factor of 2 and replication factor of 3. You must take the replication factor into account when sizing disks. Be careful when using shared storage instead of local disk. A large number of indexers can overload a single SAN.
If you are leveraging Splunk cloud, ensure you account for the on-premise Splunk instances and Universal Forwarders.
In practice, there are a large number of factors that determine Splunk performance. We recommend reaching out to your trusted Splunk advisor for help when designing a Splunk environment.
![]() In conclusion, understanding Splunk's architecture is crucial for building a well running Splunk environment. We've explored the key components, various deployment options, and best practices for optimizing your Splunk environment.
In conclusion, understanding Splunk's architecture is crucial for building a well running Splunk environment. We've explored the key components, various deployment options, and best practices for optimizing your Splunk environment.
Whether you're starting with a single-instance setup or scaling up to a multisite cluster, Splunk offers flexibility and scalability to meet your organization's unique needs. And for those looking for a hassle-free solution, Splunk Cloud provides a managed service that takes care of most of your infrastructure concerns.
Remember, successful data analytics begins with a well-designed and efficient architecture. By following the best practices outlined in this guide, you can ensure that your Splunk deployment operates smoothly, handles data effectively, and delivers valuable insights for your organization.
If you have any further questions or need assistance with your Splunk deployment, don't hesitate to reach out to our experts. Thank you for reading, and we wish you success in your Splunk journey!


